Entangled Aesthetics - Data Ethics

Every AI-generated image begins long before a user enters a prompt. It starts inside a dataset, an often invisible archive containing millions of images collected from the public internet. These datasets shape the visual vocabulary of generative models and determine what an AI system can “imagine.” Early generative systems in the 1960s and 70s, like Harold Cohen’s AARON, relied on handcrafted rules and limited training material (IBM). But the rise of deep learning in the 2010s, particularly Generative Adversarial Networks (GANs), enabled models to learn from large collections of online images (Dataversity, 2023). This marked a shift toward AI systems capable of producing highly detailed and stylistically flexible artworks. Today’s leading text-to-image systems, such as DALL·E, Midjourney, and Stable Diffusion, are trained on enormous datasets like LAION-5B, scraped from public websites at unprecedented scale (LAION, 2022). However, this scraping process collects copyrighted artworks, personal photos, portraits, and culturally sensitive material without the creators’ permission or awareness. Research shows that these datasets contain unlicensed art, racial and gender biases, explicit content, and misclassified imagery (Birhane et al., 2023). Our project examines these ethical challenges by treating the dataset as the primary creative material. By building a small, intentional dataset with transparent sourcing and ethical criteria, we aim to understand how the foundation of an AI model shapes its visual imagination.

Defining the Challenge: What Is Data Ethics in AI Art?
Consent and Ownership
One of the central ethical concerns in generative AI is the issue of consent. Artists, photographers, and everyday people discover that their work has been used in training models without credit or awareness. Tools like Have I Been Trained reveal how common this is, showing entire artist portfolios embedded inside training sets. Copyright lawsuits filed against Stability AI, Midjourney, and DeviantArt indicate a rising cultural tension around creative ownership (MIT Technology Review, 2023). When datasets are scraped automatically, meaningful consent becomes nearly impossible. This raises fundamental questions: Who owns an AI-generated image? Can an AI model ethically use data that was never offered to it?

The Dataset as Hidden Architecture
Once scraped, these massive archives become the invisible architecture of AI art. They determine which aesthetics dominate, which identities appear frequently, what styles and bodies are seen as “normal,” and which cultural perspectives get erased. Scholars such as Birhane et al. (2023) argue that datasets reproduce and amplify social inequities already present in online culture. If certain groups appear rarely or stereotypically online, the model internalizes these patterns. This makes the dataset a cultural document, not a neutral technical resource.

Aesthetic Consequences
These ethical issues have direct aesthetic consequences. Biases in a dataset influence composition, lighting, facial diversity, cultural representation, body norms, and architectural styles. Thus, ethics becomes an aesthetic question: What the AI can imagine depends on the images it has seen.

Training a custom LoRA model using a curated image dataset.
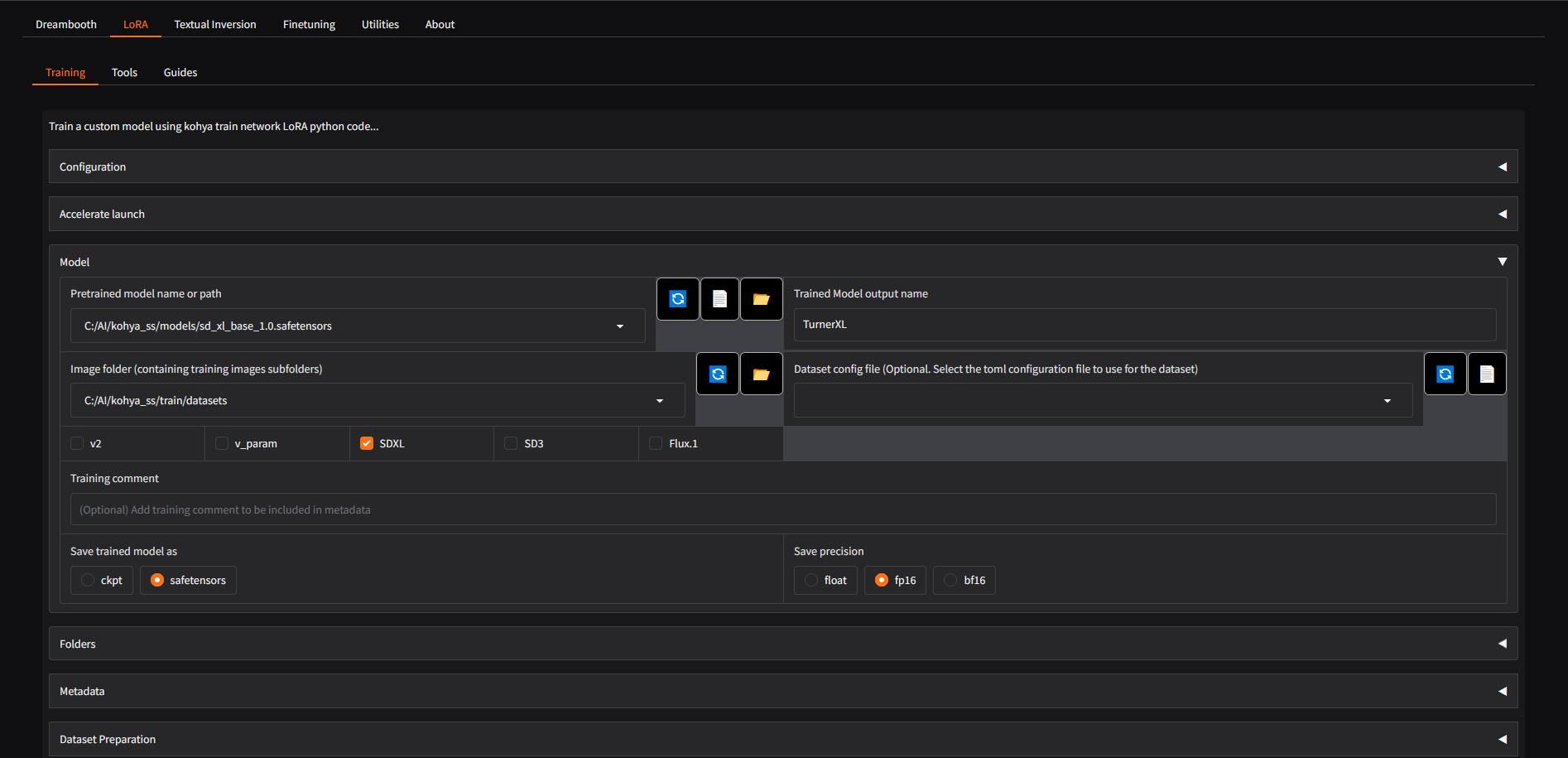
In order to further test theories and understand completely how an AI model learns patterns from copyrighted images and the resulting compositions it produces, I decided to build my own Image generator. Using Stable Diffusion for image generation and Kohya_ss for image training through open source programs on my pc, I was able to assemble a dataset that only contained works from the famous British painter JMW Turner. This allowed for careful A/B comparison between generations from the base stable diffusion model, trained on a significantly large dataset, and my locally influenced version of SD using the custom trained Turner LoRA, titled TurnerXL. The database was trained on 20 high quality Turner pngs that all share the same Nautical theme with detailed lighting, atmosphere, and clouds. This common theme allows the LoRA's influence to be easily seen in generations, especially at heavy LoRA weights.
Building the dataset and generating images
To explore how a dataset reshapes an AI model’s visual imagination, I set up a custom LoRA training workflow on my own PC using Python-based tools. I installed the Automatic1111 Stable Diffusion interface and downloaded a standard Stable Diffusion base model in .safetensors format. That base model was then loaded into kohya_ss, an open-source training toolkit, where I compiled a small, focused image database of 20 high-quality J. M. W. Turner paintings, all sharing a nautical theme with dramatic lighting, atmosphere, and clouds. Using kohya_ss, I trained a lightweight LoRA file (TurnerXL.safetensors) on this curated Turner dataset, then plugged that LoRA back into Stable Diffusion through Automatic1111. This allowed me to generate images both with the original base model and with the TurnerXL LoRA applied at different weights, making it possible to directly compare how the Turner-only training data alters composition, color, and overall style in the resulting images.



Turner Experiments
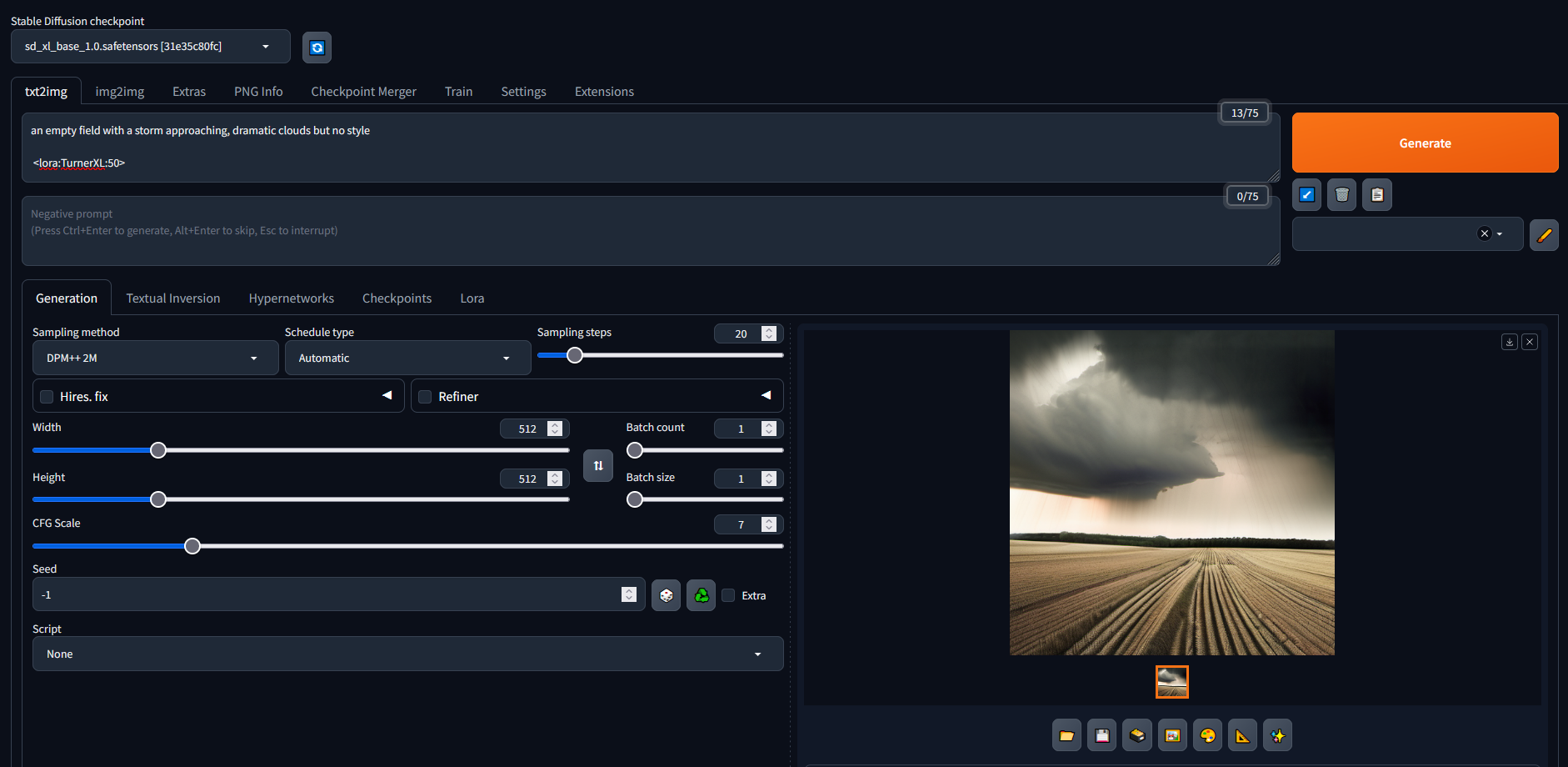
This gallery focuses on an experiment to visualize what the TurnerXL LoRA was influencing. By training the LoRA on only nautical themed paintings, it insured that the LoRA would only influence certain aspects of the generations it was assisting the base model of Stable Diffusion to create. In this case, a field of grain was chosen since this was not an element of any of the training models and would not be influenced and paired with a stormy sky, which was a common element in almost all of the Turner paintings. This would force the generation to use the base stable diffusion model to produce the field while still allowing the TurnerXL LoRA to influence the sky. Sets of 10 images were generated using the same prompt at three different LoRA weightings (how much influence the LoRA is allowed to have on the composition). Prompt: an empty field with a storm approaching, dramatic clouds but no style 0 - (0% influence NO TurnerXL LoRA) 1 - (100% influence by TurnerXL LoRA) 50 - (5000% TurnerXL LoRA influence — used to distort, saturate, and abstract the image to show areas affected by the LoRA)




Comparison Gallery
This gallery focuses on the experiment of providing the same prompt, derived by analyzing a famous painting and providing it to DALL-E 3.5, Midjourney, a base Stable Diffusion Model, and the TurnerXL LoRA influenced SD model. Can you guess the painting used? Prompt: An oil painting of a rural night sky alive with swirling motion. Thick brushstrokes catch light like waves of color; deep cobalt blues and golden yellows twist together above a small village. The texture feels almost sculpted, as if each stroke carries emotion and turbulence.

Closing Thoughts
Across hundreds of generations created to explore and understand modern image-generation tools, it becomes clear how strongly popular artwork shapes the outputs of these systems. (Much of it included in datasets without explicit permission) Iconic styles and culturally dominant imagery often become the default template that models replicate. By contrast, experimenting with a small, carefully curated Turner dataset demonstrated just how subtle the influence of a custom LoRA can be when placed against the scale and momentum of a massive base model. Even so, the TurnerXL LoRA revealed meaningful shifts in color, composition, and atmosphere, offering a glimpse into how datasets guide an AI model’s visual imagination. With more experience, computing power, and refined methods, future tests may uncover even more accurate insights into how training data shapes generative art.