Dynamic AI
Co-Creation
A Human-Centered ApproachCreated through the Digtal Pubishing Initiative at The Creative Media and Digital Culture program, with support of the OER Grants at Washington State University Vancouver.

Created through the Digtal Pubishing Initiative at The Creative Media and Digital Culture program, with support of the OER Grants at Washington State University Vancouver.

AI image generation tools like Midjourney, DALL·E, and Stable Diffusion have transformed how we create and imagine images. These systems generate pictures from text prompts, drawing on what they’ve learned from large collections of online images—including public domain art, open datasets, and copyrighted works. When you type something like "a Van Gogh landscape painting," the AI produces a new image in that style, based on its understanding of Van Gogh’s work. It doesn’t copy a specific painting, but it mimics the patterns, colors, and brushstrokes.
This kind of style imitation can help us explore how AI works, but it may not always lead to meaningful art. A better use might be to remix references—asking, for example, “What would a Van Gogh sculpture look like?” That kind of question pushes the technology into creative, unfamiliar territory. AI image generation is more than imitation—it’s a tool for visual thinking, experimentation, and surprise.
These tools are also incredibly useful in professional fields. Interior designers and architects can quickly visualize styles, color palettes, and room layouts before starting a project. Clients get to see possibilities and give feedback early, making collaboration easier. In film, AI helps directors visualize costumes, lighting, and locations during pre-production, allowing them to try different looks before committing time and money.
Educators can use AI-generated visuals to make abstract ideas more engaging. Scientists might create new kinds of diagrams, visualizations, or artistic representations of their research. And artists can explore wild new ideas—experimenting with style, symbolism, and visual form in ways that traditional tools can’t easily support.
But AI image generation also raises serious legal and ethical questions. Who owns an image created by a machine? If it mimics the style of a real artist, is that fair use or is it copying? Some argue that these systems transform existing work enough to be legal. Others believe AI companies should license any copyrighted materials used in training. And what about images with no human author at all—can they even be copyrighted?
There are also risks of misuse. AI can be used to generate fake or misleading images—so-called “deepfakes”—that blur the line between real and fake. As these technologies evolve, new laws and guidelines are needed. At the same time, there’s incredible value in using AI creatively and ethically. It’s a tool that can extend human imagination, not replace it.

Generative Adversarial Networks, or GANs, are a type of AI used to create new images. They work by combining two systems: a generator, which creates images, and a discriminator, which judges them. You can think of the generator as an artist and the discriminator as a critic. The artist tries to create realistic images, while the critic tries to spot what’s fake. Over time, the generator improves its skill by learning from this feedback.

GANs use something called latent space—an invisible map of ideas. Each spot in this space represents a different kind of image. When the AI picks a location (called a latent vector), the generator turns that point into an image. Nearby points in latent space produce similar images, while distant points make very different ones.

As the GAN trains, the generator learns to make better, more realistic images. But GANs aren’t perfect. They can run into problems like mode collapse, where the AI keeps generating the same type of image, or training instability, where learning gets stuck. Still, GANs opened the door to the idea of machines having a kind of “synthetic imagination”—generating new visuals based on what they’ve learned.

Diffusion models are another major approach to AI image generation, and they’ve become more popular than GANs. These models work very differently. Instead of learning to trick a critic, diffusion models start with random noise—like TV static—and gradually turn it into a detailed image through a process called denoising.
This is like sculpting from chaos: the model learns how to remove bits of noise step by step, until a clear image appears. It’s based on how particles spread (or “diffuse”) in physics, but done in reverse. Because of this step-by-step method, diffusion models are very stable during training and produce high-quality, photorealistic images.
Both GANs and diffusion models have their strengths. GANs are fast and good for real-time applications. Diffusion models are slower but more reliable and capable of stunning detail. In recent years, diffusion has become the go-to technique for high-end creative work because of its stability and flexibility.
Looking ahead, we may see hybrid models that combine the strengths of both systems. Diffusion models are also now being used in video generation, where their frame-by-frame refinement is ideal for motion and texture. As these tools continue to evolve, they’ll give artists and designers more powerful ways to create, imagine, and experiment with visual ideas.

The first AI artwork to be sold at auction, Edmond de Belamy, marked a groundbreaking moment in the art world, showcasing the novel capabilities of machine-generated creativity. Created by the Paris-based art collective Obvious, this portrait was not painted by a human hand but by a machine. Utilizing a Generative Adversarial Network (GAN), the AI was trained on a dataset of 15,000 portraits spanning six centuries. The resulting piece, characterized by its hauntingly abstract features, reflects the essence of classic portraiture while simultaneously challenging traditional notions of artistry. When Edmond de Belamy was auctioned at Christie’s in 2018, it fetched an astonishing $432,500, far exceeding initial estimates. This sale highlighted the profound potential of AI in art, demonstrating that, with the right data and algorithms, machines can produce works that are both innovative and evocative, without direct human intervention beyond their initial programming.
While AI tools like GANs and diffusion models can generate images on their own, many artists prefer to use AI as a creative partner—not just a machine that makes art for them. Here are some of the key ways artists use AI to support and expand their own creative process:
In all these cases, the human artist is in the driver’s seat. AI is a powerful assistant, but it’s the artist who provides direction, selects what works, and makes the final creative choices. This kind of collaboration turns AI into a creative companion—one that supports exploration, ideation, and refinement while amplifying the artist’s unique voice.
AI-powered image creation has exploded in recent years, giving rise to a wide array of tools that support artists, designers, educators, and creators in transforming ideas into visual outputs. These platforms use different AI models—mostly based on diffusion techniques—and offer varying degrees of control, quality, and customization.
These tools are evolving rapidly, with new features being released monthly. Because most are browser-based or app-integrated, creators at all skill levels—from students to professional designers—can now generate, edit, and experiment with high-quality visuals in just minutes.
While the AI art tools themselves are impressive technological marvels, equally essential are the pioneering human artists pushing the boundaries of how this tech can expand modes of creative expression and communication. Notable AI artists include:
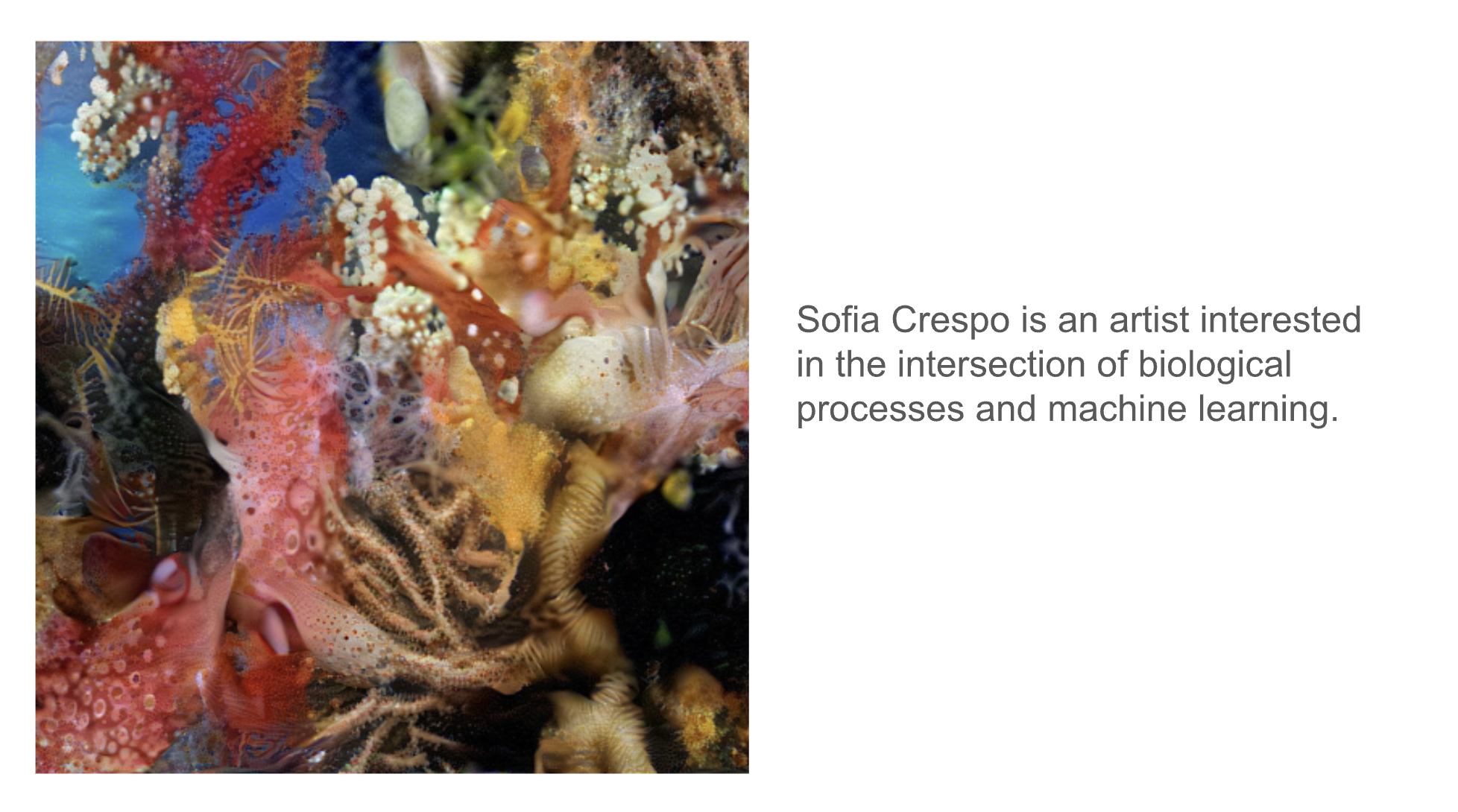
Sofia Crespo is a pioneering artist whose work focuses on the intersection of biology and artificial intelligence. She uses AI models, particularly GANs and neural networks, to create intricate digital art pieces that explore the relationship between natural and artificial life forms. Her work often features organic shapes and textures reminiscent of biological entities, reflecting on how AI can mimic and interpret the complexities of the natural world. Crespo’s notable projects include "Neural Zoo," where she generates images of speculative creatures and plants that do not exist in reality but appear convincingly organic, challenging our perceptions of nature and machine-generated art.

Sougwen Chung is an interdisciplinary artist who explores the relationship between humans and machines through collaborative drawings and installations. Her work frequently involves drawing alongside robotic arms controlled by AI systems that learn from her style. This ongoing human-AI collaboration, as seen in her project "Drawing Operations," highlights the evolving nature of co-creativity and questions the role of autonomy in artistic creation. Chung’s practice bridges art, performance, and technology, offering a poetic exploration of how humans and machines can create together.

Refik Anadol is an artist known for his immersive installations that transform data into visually stunning and thought-provoking art pieces. He leverages AI and machine learning algorithms to process large datasets, such as urban landscapes, social media interactions, and cultural archives, turning them into dynamic visualizations and media sculptures. Anadol's work often involves projecting these data-driven visuals onto architectural surfaces, creating a seamless blend of the physical and digital realms. His projects like "Infinity Room" and "Melting Memories" push the boundaries of how data can be experienced aesthetically, offering a glimpse into the future of media art and the potential of AI to reshape our interaction with information.

Anna Ridler is an artist who works with both AI and data to explore themes of narrative, storytelling, and ownership of information. She often creates hand-annotated datasets, which are then used to train AI models, allowing her to maintain creative control over the outputs. One of her most well-known works is "Mosaic Virus," where she used a dataset of tulip images to comment on historical tulip mania and contemporary financial bubbles. Ridler’s work offers a thoughtful examination of how humans can shape the datasets that AI learns from, turning the creative process into a more personal and intentional act.

Ben Snell is an artist who uses artificial intelligence to explore the intersection of human creativity and machine learning. He trains custom AI models on datasets of his own sculptures, letting the machine generate new forms that he then brings into physical existence. By transforming AI-generated concepts into tangible objects, Snell's work investigates the evolving relationship between creator and tool, and the ways in which machines can co-author the artistic process. His project "Dio" involved feeding a computer's physical body back into the machine, creating a self-referential loop of artistic creation.

Roman Lipski is a Polish painter who collaborates with artificial intelligence to push the boundaries of his artistic practice. Through a constant exchange between the artist and an AI system, Lipski's work has evolved into a process of co-creation where the machine suggests novel ideas based on his past works. His "Unfinished" series is an ongoing dialogue between human intuition and machine learning, where AI not only inspires but also influences the creative process. This partnership explores the potential of AI to expand human imagination and challenges traditional notions of authorship in the arts.
This exercise guides you through using AI tools to help design, develop, and reflect on a short comic. It combines sketching, prompting, editing, and artistic decision-making.